Intro to web-scraping
work-in-progress
It is hard to tell about the web-scraping given a limited lecture & seminar time. Here, I include two examples of data which is easy to collect when you are determined to do that. The code is commented inside the chunks, but make sure to google each function you do not understand, watch tutotials, and put these skills to practice.
We will build two networks:
wikipedia links among the pages devoted to 950 sociologists,
relations among the 500 R packages.
library(data.table)
library(tidyverse)
library(rvest)
library(furrr)
library(igraph)
library(netUtils)
library(tictoc)
library(tidytext)Wikipedia example: relations among 950 pages about sociologists
I took this set of pages because (1) it is a relatively small list of pages that (2) actually constitutes a medium-sized network. So, it takes little time to parse and simultaneously allows to show you how to proceed with data collection.
Note that there is a specialized package WikipediR that simplifies the process of collecting data from the Wikipedia. I use rvest just because it is a generalizable solution which can be tailored to be used in other websites containing many interconnected pages. To learn more about rvest, you can consult:
See the code chunks below to learn the process. First, we need to get the list of pages we want to get data about. Usually, these pages are equal to agents who will take part in our networks. So, we initially get the nodelist:
## ---------------------------------
## link to the list of sociologists:
## ---------------------------------
url = "https://en.wikipedia.org/wiki/List_of_sociologists"
## get their names and links to wikipedia pages:
df1 <- data.frame(link = url %>%
read_html() %>%
html_nodes(css = '.noprint+ ul li > a:nth-child(1)') %>%
html_attr("href"),
person = url %>%
read_html() %>%
html_nodes(css = '.noprint+ ul li > a:nth-child(1)') %>%
html_text())
## descriptions:
df2 <- url %>%
read_html() %>%
html_nodes(css = '.noprint+ ul li') %>%
html_text() %>%
data.frame(person_info = .)
## remove a single person without a personal page:
df3 <- df1 %>%
bind_cols(df2 %>%
filter(person_info != "Rodrigo Jokisch (born 1946), German-Mexican sociologist and social theorist"))
rm(df1, df2, url)Next, our task is to get the data about the connections present among these pages (actors) - an edgelist. We can get it by (1) collecting the links included in the nodes’ pages and (2) filter the obtained list of ties by the nodelist. Here is how we can do that.
Note that I use parallelization to collect all these pages. I utilize the furrr package, but (1) there are other options, like doParallel, (2) and more optimal script variants
(it’s best not to run it all together in the classroom, to avoid ruining Wikipedia)
(once again, there are also special packages for working with the Wikipedia API; you can download it through them as well. However, the general-purpose code is an example of working with static, non-banned sites)
## ----------------------------------
## get links from the personal pages:
## ----------------------------------
## this solution might be not very ethnical due to speed:
plan(multisession(workers = 12)) ## library(furrr), n parallel sessions
tic()
results_wiki = future_map(str_c("https://en.wikipedia.org",
df3[1:953,1]), ## vector of links
function(x) {
tryCatch({
links_to <- x %>%
read_html() %>%
html_nodes(css = "a") %>% ## get ALL links present
html_attr("href") %>%
data.frame(to = .) %>%
filter(to %in% df3$link) ## filter links by our initial list
## page id:
if(nrow(links_to) > 0){
links_to$from = as.character(x)
}
return(links_to)
Sys.sleep(0.5)
})
})
toc() ## 37 seconds on 953 pages, on my local device and local connectionWe can now extract all the collected links into one long list of edges:
#write_rds(results_wiki,
# "results_wiki.rds")
results_wiki <- read_rds("datasets/results_wiki.rds")
results_binded <- Reduce(function(x, y) bind_rows(x, y),
results_wiki)Next, remove the so-called loops (connections of a node to itself) and duplicate connections (multiple links to the same page from the same page):
edges <- results_binded %>%
mutate(from = str_remove_all(from,
"https\\:\\/\\/en\\.wikipedia\\.org")) %>%
filter(to != from) %>%
select(from, to) %>%
graph_from_data_frame(directed = T) %>%
simplify() %>%
igraph::as_data_frame(what = "edges") ## 10,622 edgesBefore we proceed with the network, let’s extract from the sociologists’ short descriptions their countries of origin:
#df3 %>%
# group_by(link, person) %>%
# slice(1) %>%
# ungroup() %>%
# unnest_tokens(token,person_info) %>%
# count(token) %>%
# filter(!token %in% stopwords::stopwords("en")) %>%
# arrange(desc(n))
df3 <- df3 %>%
mutate(background = str_extract(tolower(person_info), ## does not account for mixed cases
"american|french|british|german|canadian|russian|indian|italian|mexican|austrian|danish|english|polish|brazilian|argentinian")) %>%
mutate(background = ifelse(background == "english",
"british",
background))
df3 %>%
count(background) %>%
arrange(desc(n))
#> background n
#> 1 american 371
#> 2 <NA> 136
#> 3 british 106
#> 4 french 100
#> 5 german 85
#> 6 russian 20
#> 7 canadian 19
#> 8 indian 18
#> 9 italian 18
#> 10 austrian 16
#> 11 danish 15
#> 12 mexican 14
#> 13 polish 13
#> 14 brazilian 12
#> 15 argentinian 10Create igraph object:
g.wiki.soc <- graph_from_data_frame(edges,
vertices = df3 %>%
group_by(link, person) %>%
slice(1) %>%
ungroup(),
directed = T)
g.wiki.soc
#> IGRAPH 30fec6c DN-- 950 10622 --
#> + attr: name (v/c), person (v/c), person_info (v/c),
#> | background (v/c)
#> + edges from 30fec6c (vertex names):
#> [1] /wiki/Andrew_Abbott_(sociologist)->/wiki/Morris_Janowitz
#> [2] /wiki/Andrew_Abbott_(sociologist)->/wiki/Edward_Shils
#> [3] /wiki/Mark_Abrams ->/wiki/R._H._Tawney
#> [4] /wiki/Mark_Abrams ->/wiki/Michael_Young,_Baron_Young_of_Dartington
#> + ... omitted several edgesSince the network is not integral, we should look at the component sizes (to justify the further work with only the largest component):
igraph::components(g.wiki.soc) %>%
str()## 226 components --> one large component, one dyad, others isolated
#> List of 3
#> $ membership: Named num [1:950] 1 1 1 1 1 1 1 2 1 1 ...
#> ..- attr(*, "names")= chr [1:950] "/wiki/%C3%81gnes_Heller" "/wiki/%C3%89lisabeth_Badinter" "/wiki/%C3%89mile_Durkheim" "/wiki/%C3%89mile_Littr%C3%A9" ...
#> $ csize : num [1:226] 718 1 1 1 1 1 1 1 1 1 ...
#> $ no : num 226
g.wiki.soc.biggest <- netUtils::biggest_component(g.wiki.soc)
g.wiki.soc.biggest
#> IGRAPH 310f48d DN-- 718 10613 --
#> + attr: name (v/c), person (v/c), person_info (v/c),
#> | background (v/c)
#> + edges from 310f48d (vertex names):
#> [1] /wiki/Andrew_Abbott_(sociologist)->/wiki/Morris_Janowitz
#> [2] /wiki/Andrew_Abbott_(sociologist)->/wiki/Edward_Shils
#> [3] /wiki/Mark_Abrams ->/wiki/R._H._Tawney
#> [4] /wiki/Mark_Abrams ->/wiki/Michael_Young,_Baron_Young_of_Dartington
#> + ... omitted several edgesDone!
Although the results can be more interesting once you find a more intriguing list of actors. It can be about cultural production (lists of writers, lists of architects), countries’ relations (generalized, not concrete), chemical elements, or anything else. If you want to collect Wikipedia data for your project, though, remember that these ties should be interpreted carefully as the referecing in Wikipedia can be weird (we cannot say, for example, that ties among the writers’ pages constitute the relations of respect or friendship - they in fact consitute a long-long list of possible types of relations).
Just for fun, below is a small analysis of the given graph. I start by computing some measures already familiar to you:
diameter(g.wiki.soc.biggest) ## 10
#> [1] 10
mean_distance(g.wiki.soc.biggest) ## 3.31
#> [1] 3.313099
netseg::orwg(g.wiki.soc.biggest,
"background") ## 3.54, homophily, interpret as odds-ratios
#> [1] 3.54002
reciprocity(g.wiki.soc.biggest) ## 0.72, meaning 72% of ties are mutual
#> [1] 0.7236408Check for the core/periphery:
cp <- netUtils::core_periphery(g.wiki.soc.biggest)
#cp %>%
# str()
V(g.wiki.soc.biggest)$core.periphery = cp$vec
#g.wiki.soc.biggest %>%
# as_data_frame(what = "vertices") %>%
# count(core.periphery)
par(mar=c(0,0,0,0))
set.seed(31)
g.wiki.soc.biggest %>%
plot(vertex.label = NA,
vertex.size = 2,
vertex.color = ifelse(V(g.wiki.soc.biggest)$core.periphery == 1,
"coral1",
"grey60"),
edge.color = "black",
edge.size = 1,
edge.arrow.size = 0.5, edge.arrow.width = 0.4)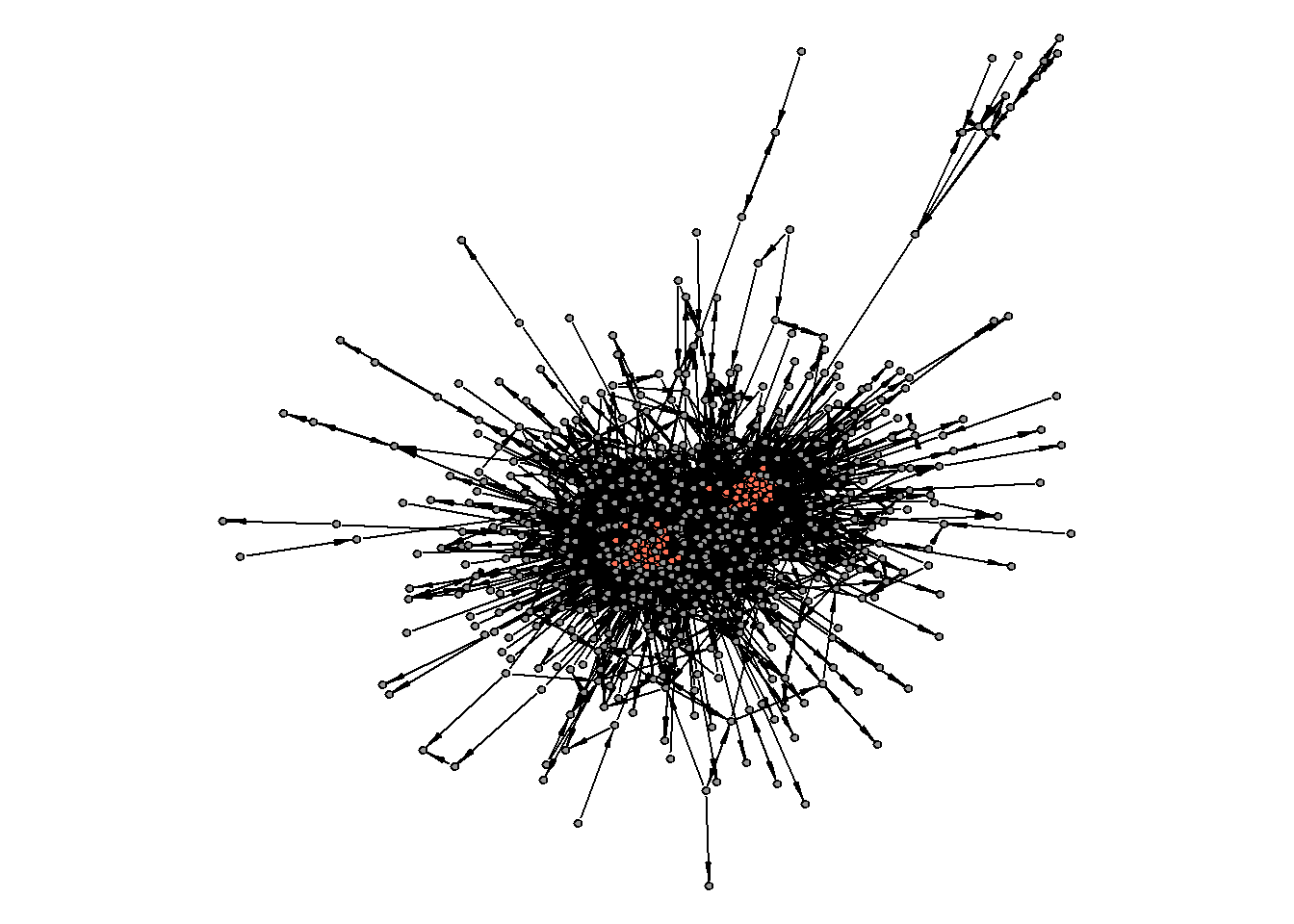
Something seems to be off with the produced core/periphery partition. What about the community structure?
par(mfrow = c(2,2))
for(i in c(0.3, 0.6, 0.9, 1.2)){
set.seed(31)
cl <- cluster_louvain(g.wiki.soc.biggest %>%
as_undirected(),
resolution = i)
V(g.wiki.soc.biggest)$cluster = cl$membership
par(mar=c(0,0,0,0))
set.seed(31)
g.wiki.soc.biggest %>%
plot(vertex.label = NA,
vertex.size = 4,
vertex.color = V(g.wiki.soc.biggest)$cluster,
edge.color = "black",
edge.size = 1,
main = str_c("\ni = ",
i,
"#: ",
V(g.wiki.soc.biggest)$cluster %>%
max()),
edge.arrow.size = 0.5,
edge.arrow.width = 0.4)
}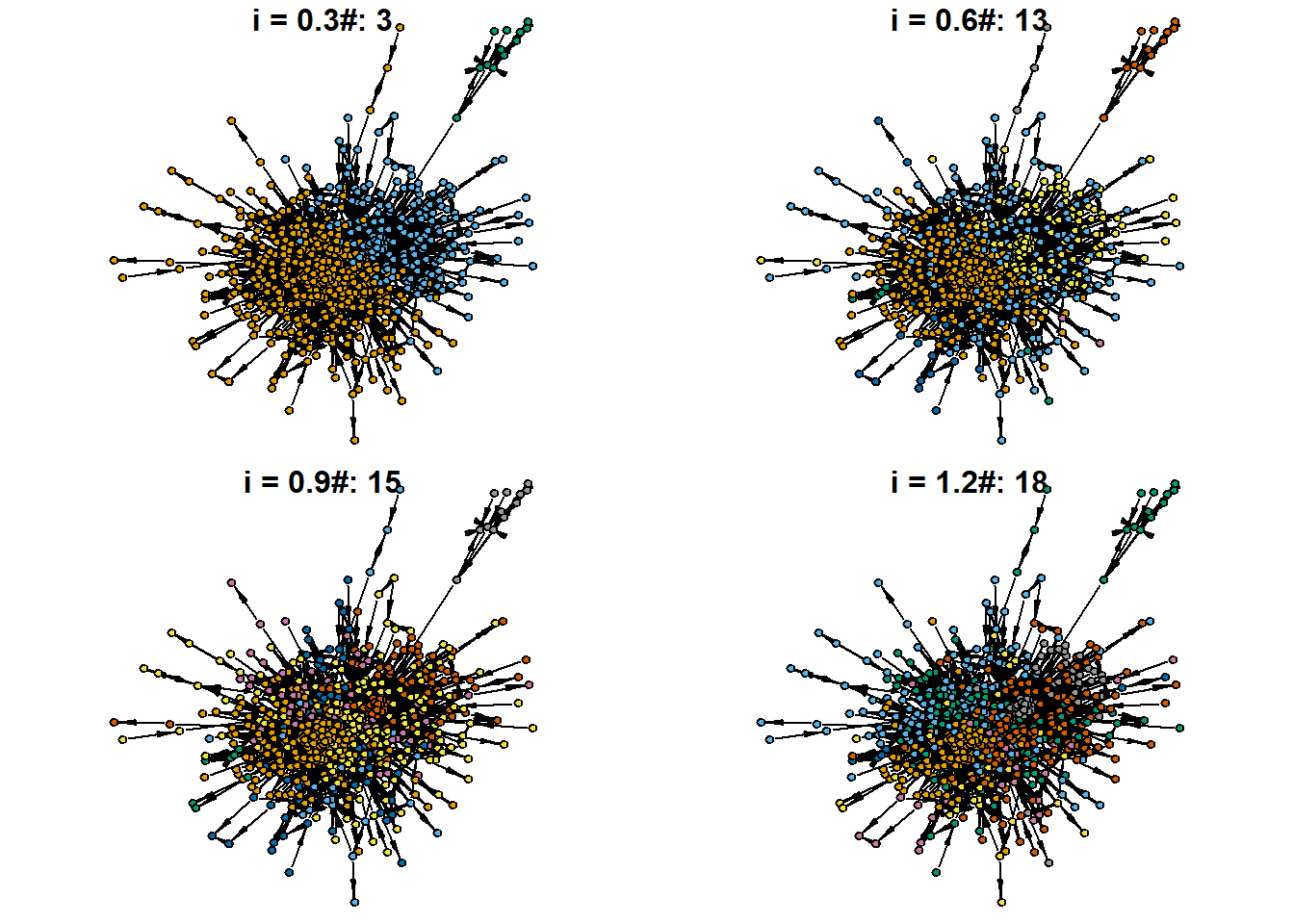
I attach to our graph object the solution with only three communities (also there are clearly 2: U.S. vs. European communities, in historical perspective):
set.seed(31)
cl <- cluster_louvain(g.wiki.soc.biggest %>%
as_undirected(),
resolution = 0.3)
V(g.wiki.soc.biggest)$cluster = cl$membershipCentrality measures:
V(g.wiki.soc.biggest)$indegree = igraph::degree(g.wiki.soc.biggest, mode = "in")
V(g.wiki.soc.biggest)$outdegree = igraph::degree(g.wiki.soc.biggest, mode = "out")
V(g.wiki.soc.biggest)$betweenness = igraph::betweenness(g.wiki.soc.biggest)
V(g.wiki.soc.biggest)$closeness = igraph::closeness(g.wiki.soc.biggest, mode = "total")
V(g.wiki.soc.biggest)$eigen = igraph::eigen_centrality(g.wiki.soc.biggest)$vectorDegree centrality vs. betweenness (to detect, as you know, globally central, locally central, brokering, and margianl nodes):
g.wiki.soc.biggest %>%
as_data_frame(what = "vertices") %>%
ggplot(aes(indegree,betweenness)) +
geom_point() +
ggrepel::geom_text_repel(aes(label = person), size = 2.8)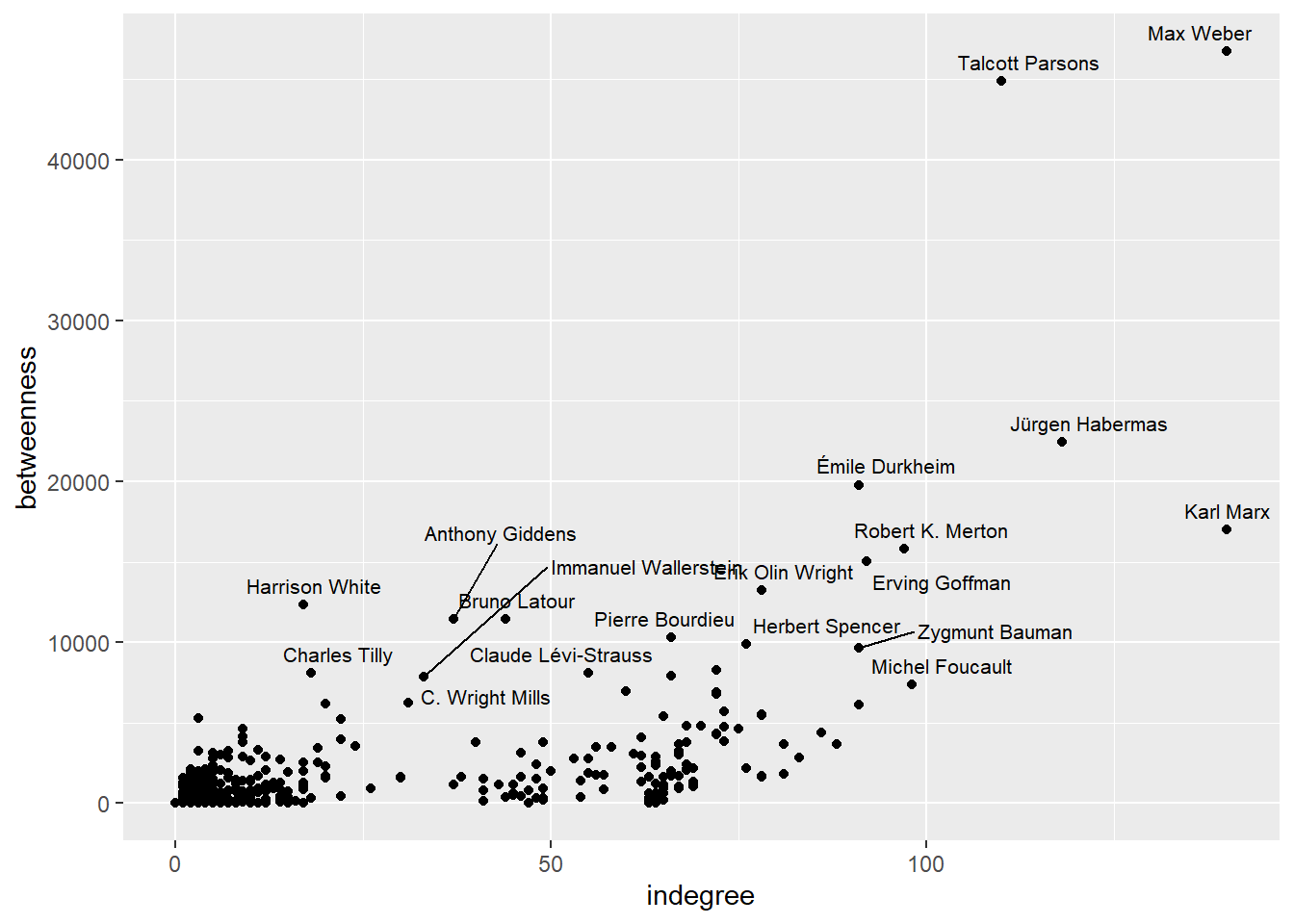
Highest eigenvector scores:
g.wiki.soc.biggest %>%
as_data_frame(what = "vertices") %>%
top_n(15, eigen) %>%
select(person, indegree, outdegree, eigen) %>%
arrange(desc(eigen))
#> person
#> /wiki/Talcott_Parsons Talcott Parsons
#> /wiki/Erving_Goffman Erving Goffman
#> /wiki/Robert_K._Merton Robert K. Merton
#> /wiki/Erik_Olin_Wright Erik Olin Wright
#> /wiki/Lester_Frank_Ward Lester Frank Ward
#> /wiki/Seymour_Martin_Lipset Seymour Martin Lipset
#> /wiki/Alejandro_Portes Alejandro Portes
#> /wiki/Douglas_Massey Douglas Massey
#> /wiki/Neil_Smelser Neil Smelser
#> /wiki/William_Graham_Sumner William Graham Sumner
#> /wiki/James_Samuel_Coleman James Samuel Coleman
#> /wiki/Patricia_Hill_Collins Patricia Hill Collins
#> /wiki/Florian_Znaniecki Florian Znaniecki
#> /wiki/George_C._Homans George C. Homans
#> /wiki/Everett_Hughes_(sociologist) Everett Hughes
#> indegree outdegree
#> /wiki/Talcott_Parsons 110 123
#> /wiki/Erving_Goffman 92 74
#> /wiki/Robert_K._Merton 97 74
#> /wiki/Erik_Olin_Wright 78 67
#> /wiki/Lester_Frank_Ward 73 65
#> /wiki/Seymour_Martin_Lipset 75 68
#> /wiki/Alejandro_Portes 72 65
#> /wiki/Douglas_Massey 73 65
#> /wiki/Neil_Smelser 70 65
#> /wiki/William_Graham_Sumner 68 66
#> /wiki/James_Samuel_Coleman 72 61
#> /wiki/Patricia_Hill_Collins 72 69
#> /wiki/Florian_Znaniecki 64 63
#> /wiki/George_C._Homans 68 63
#> /wiki/Everett_Hughes_(sociologist) 67 62
#> eigen
#> /wiki/Talcott_Parsons 1.0000000
#> /wiki/Erving_Goffman 0.9772865
#> /wiki/Robert_K._Merton 0.9763853
#> /wiki/Erik_Olin_Wright 0.9685004
#> /wiki/Lester_Frank_Ward 0.9653630
#> /wiki/Seymour_Martin_Lipset 0.9631846
#> /wiki/Alejandro_Portes 0.9626278
#> /wiki/Douglas_Massey 0.9625743
#> /wiki/Neil_Smelser 0.9624601
#> /wiki/William_Graham_Sumner 0.9618256
#> /wiki/James_Samuel_Coleman 0.9595931
#> /wiki/Patricia_Hill_Collins 0.9594090
#> /wiki/Florian_Znaniecki 0.9593397
#> /wiki/George_C._Homans 0.9589332
#> /wiki/Everett_Hughes_(sociologist) 0.9585830500 CRAN packages, related
For the second example utilizing the same logic, I collect the data from the Comprehensive R Archive Network (CRAN)
cran <- "https://www.datasciencemeta.com/rpackages" %>%
read_html()
links <- cran %>%
html_nodes('a') %>%
html_attr('href')
texts <- cran %>%
html_nodes('a') %>%
html_text()
downloads <- cran %>%
html_nodes('td:nth-child(3)') %>%
html_text()
cran <- data.frame(package = texts,
link = links,
downloads = downloads) %>%
mutate(package_id = str_remove_all(link,
"https://cran.r-project.org/web/packages"))The script below collects the data for the first 500 packages (by the number of downloads). The approach is similar, but this time with a regular loop (no parallel execution):
edges <- data.frame()
tic()
for(i in c(1:500)){
links_to <- cran[i,2] %>%
as.character() %>%
read_html() %>%
html_nodes(css = "a, .CRAN") %>%
html_attr("href") %>%
data.frame(to = .) %>%
filter(str_detect(to, "/index.html$")) %>%
mutate(to = str_extract(to, "/.+/index\\.html$")) %>%
filter(to %in% cran$package_id)
if(nrow(links_to) > 0){
links_to$from = as.character(cran[i,4])
}
edges <- edges %>%
bind_rows(links_to)
#print(i)
}
toc() ## 194 secondsConstruct the igraph object:
#write_rds(edges, "datasets/cran-network.rds")
edges <- read_rds("datasets/cran-network.rds")
g.cran <- edges %>%
filter(to %in% cran[1:500,4]) %>%
graph_from_data_frame()Compute centrality measures and detect communities (no Sherlocking for this example):
V(g.cran)$degree = igraph::degree(g.cran, mode = "in")
set.seed(32)
V(g.cran)$group = cluster_louvain(g.cran %>%
as_undirected(),
resolution = 0.5) %>%
membership()
par(mar=c(0,0,0,0))
g.cran %>%
plot(vertex.label = NA,
vertex.size = V(g.cran)$degree/15,
vertex.color = V(g.cran)$group,
edge.color = "grey",
edge.arrow.width = 0.1,
edge.width = 0.1)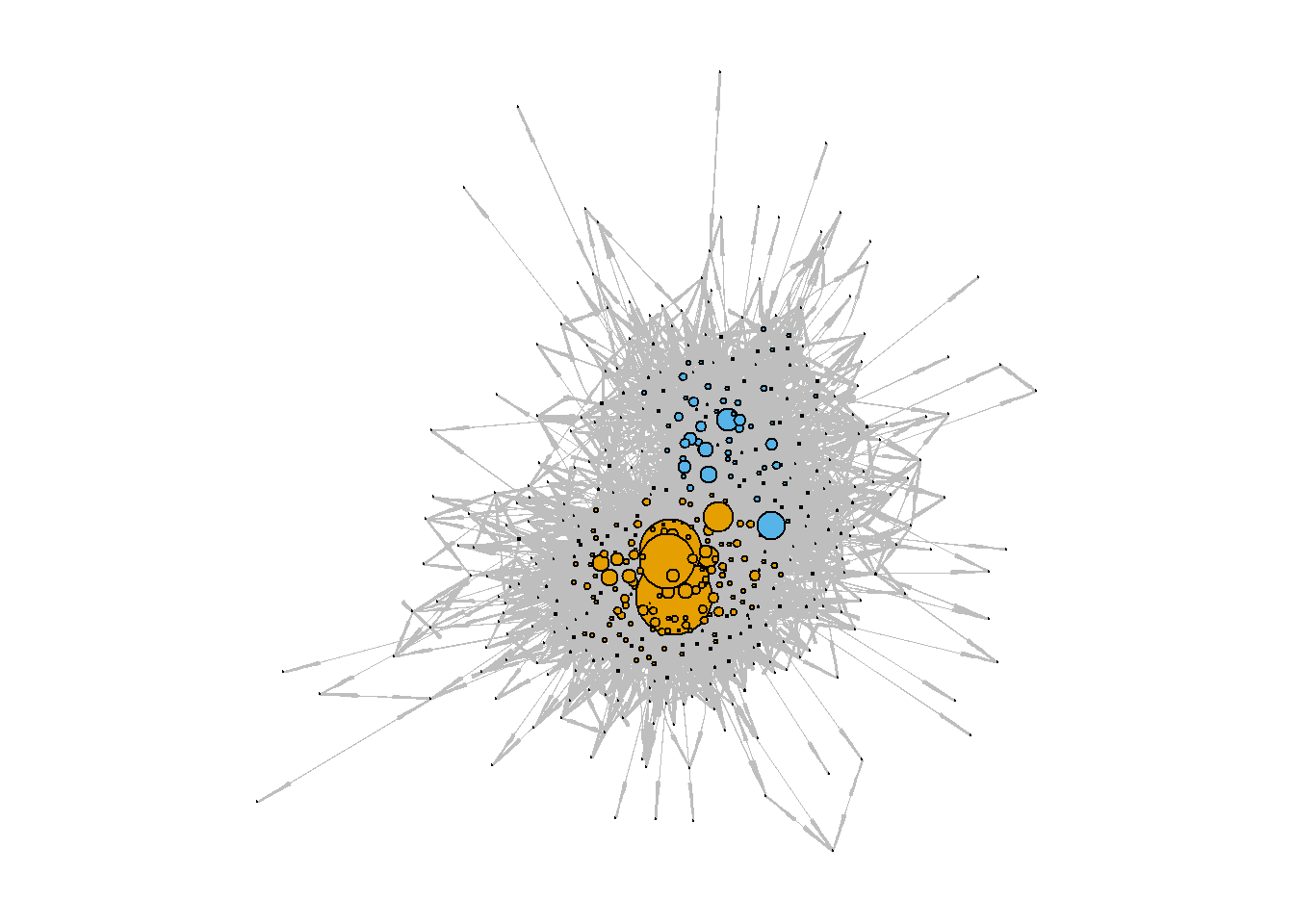
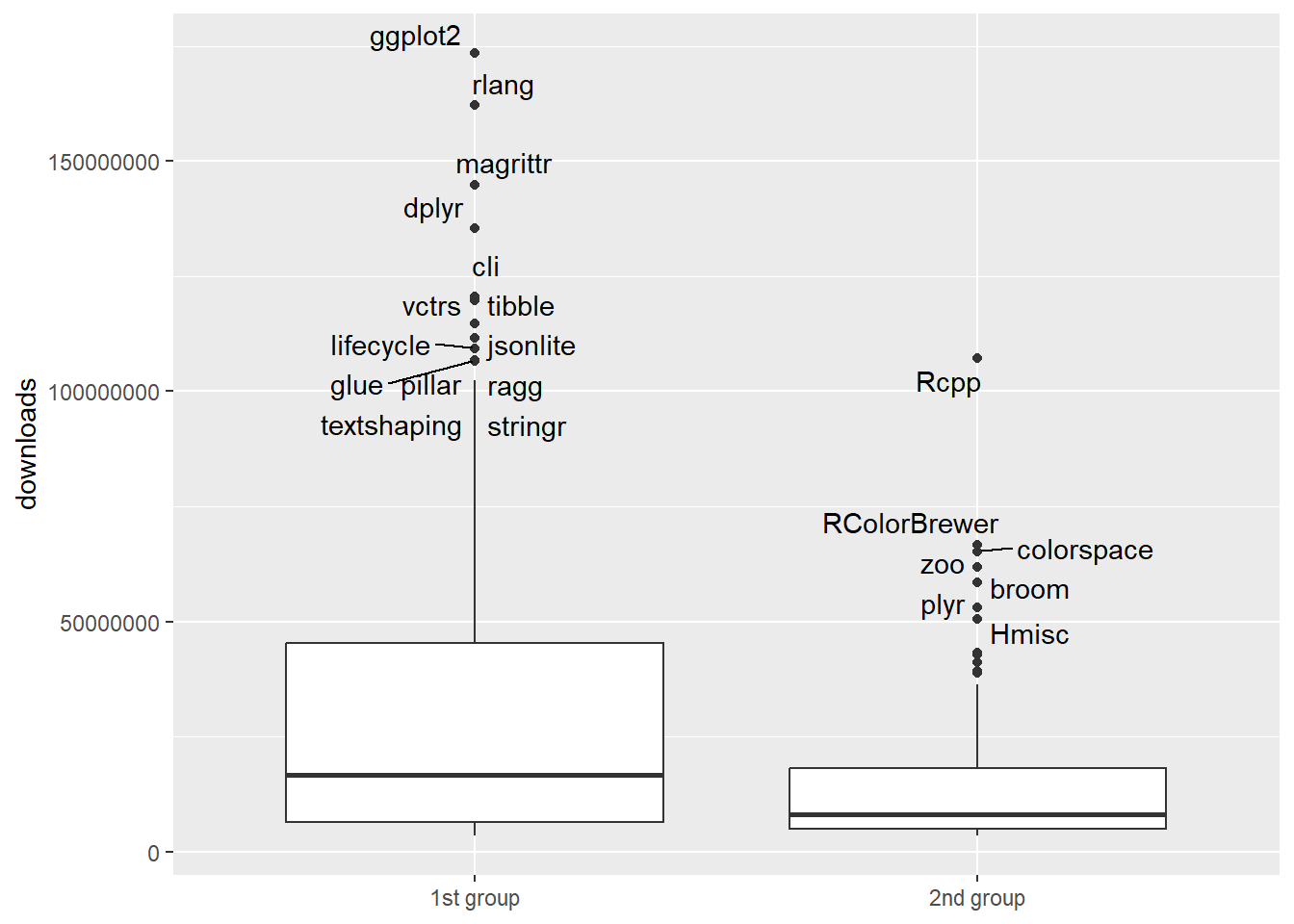
Compare the distributions of “downloads” scores:
options(scipen = 999)
g.cran %>%
igraph::as_data_frame(what = "vertices") %>%
rename(package_id = name) %>%
left_join(cran) %>%
mutate(downloads = as.numeric(str_remove_all(downloads, ",")),
group = as.factor(group)) %>%
ggplot(aes(group, downloads)) +
geom_boxplot() +
ggrepel::geom_text_repel(aes(label = package)) +
scale_x_discrete(labels = c("1st group", "2nd group")) +
labs(x = NULL)